

原文作者:Vijini Mallawaarachchi
原文地址:10 Common Software Architectural Patterns in a nutshell
有没有想过要设计多大的企业规模系统?在主要的软件开发开始之前,我们必须选择一个合适的体系结构,它将为我们提供所需的功能和质量属性。因此,在将它们应用到我们的设计之前,我们应该了解不同的体系结构。

什么是架构模式?
根据维基百科中的定义:
架构模式是一个通用的、可重用的解决方案,用于在给定上下文中的软件体系结构中经常出现的问题。架构模式与软件设计模式类似,但具有更广泛的范围。
在本文中,将简要地解释以下10种常见的体系架构模式,以及它们的用法、优缺点。
- 分层模式
- 客户端-服务器模式
- 主从设备模式
- 管道-过滤器模式
- 代理模式
- 点对点模式
- 事件总线模式
- 模型-视图-控制器模式
- 黑板模式
- 解释器模式
一. 分层模式
这种模式也称为多层体系架构模式。它可以用来构造可以分解为子任务组的程序,每个子任务都处于一个特定的抽象级别。每个层都为下一个提供更高层次服务。
一般信息系统中最常见的是如下所列的4层。
- 表示层(也称为UI层)
- 应用层(也称为服务层)
- 业务逻辑层(也称为领域层)
- 数据访问层(也称为持久化层)
使用场景:
- 一般的桌面应用程序
- 电子商务Web应用程序

二. 客户端-服务器模式
这种模式由两部分组成:一个服务器和多个客户端。服务器组件将为多个客户端组件提供服务。客户端从服务器请求服务,服务器为这些客户端提供相关服务。此外,服务器持续侦听客户机请求。
使用场景:
- 电子邮件,文件共享和银行等在线应用程序

三. 主从设备模式
这种模式由两方组成;主设备和从设备。主设备组件在相同的从设备组件中分配工作,并计算最终结果,这些结果是由从设备返回的结果。
使用场景:
- 在数据库复制中,主数据库被认为是权威的来源,并且要与之同步
- 在计算机系统中与总线连接的外围设备(主和从驱动器)

四. 管道-过滤器模式
此模式可用于构造生成和处理数据流的系统。每个处理步骤都封装在一个过滤器组件内。要处理的数据是通过管道传递的。这些管道可以用于缓冲或用于同步。
使用场景:
- 编译器。连续的过滤器执行词法分析、解析、语义分析和代码生成
- 生物信息学的工作流

五. 代理模式
此模式用于构造具有解耦组件的分布式系统。这些组件可以通过远程服务调用彼此交互。代理组件负责组件之间的通信协调。
服务器将其功能(服务和特征)发布给代理。客户端从代理请求服务,然后代理将客户端重定向到其注册中心的适当服务。
使用场景:
- 消息代理软件,如Apache ActiveMQ,Apache Kafka,RabbitMQ和JBoss Messaging

六. 点对点模式
在这种模式中,单个组件被称为对等点。对等点可以作为客户端,从其他对等点请求服务,作为服务器,为其他对等点提供服务。对等点可以充当客户端或服务器或两者的角色,并且可以随时间动态地更改其角色。
使用场景:
- 像Gnutella和G2这样的文件共享网络
- 多媒体协议,如P2PTV和PDTP
- 像Spotify这样的专有多媒体应用程序

七. 事件总线模式
这种模式主要是处理事件,包括4个主要组件:事件源、事件监听器、通道和事件总线。消息源将消息发布到事件总线上的特定通道上。侦听器订阅特定的通道。侦听器会被通知消息,这些消息被发布到它们之前订阅的一个通道上。
使用场景:
- 安卓开发
- 通知服务

八. 模型-视图-控制器模式
这种模式,也称为MVC模式,把一个交互式应用程序划分为3个部分,
- 模型:包含核心功能和数据
- 视图:将信息显示给用户(可以定义多个视图)
- 控制器:处理用户输入的信息
这样做是为了将信息的内部表示与信息的呈现方式分离开来,并接受用户的请求。它分离了组件,并允许有效的代码重用。
使用场景:
- 在主要编程语言中互联网应用程序的体系架构
- 像Django和Rails这样的Web框架

九. 黑板模式
这种模式对于没有确定解决方案策略的问题是有用的。黑板模式由3个主要组成部分组成。
- 黑板——包含来自解决方案空间的对象的结构化全局内存
- 知识源——专门的模块和它们自己的表示
- 控制组件——选择、配置和执行模块
所有的组件都可以访问黑板。组件可以生成添加到黑板上的新数据对象。组件在黑板上查找特定类型的数据,并通过与现有知识源的模式匹配来查找这些数据。
使用场景:
- 语音识别
- 车辆识别和跟踪
- 蛋白质结构识别
- 声纳信号的解释

十. 解释器模式
这个模式用于设计一个解释用专用语言编写的程序的组件。它主要指定如何评估程序的行数,即以特定的语言编写的句子或表达式。其基本思想是为每种语言的符号都有一个分类。
使用场景:
- 数据库查询语言,比如SQL
- 用于描述通信协议的语言

体系架构模式的比较
下面给出的表格总结了每种体系架构模式的优缺点。
| 名称 | 优点 | 缺点 |
|---|---|---|
| 分层模式 | 一个较低的层可以被不同的层所使用。层使标准化更容易,因为我们可以清楚地定义级别。可以在层内进行更改,而不会影响其他层。 | 不是普遍适用的。在某些情况下,某些层可能会被跳过。 |
| 客户端-服务器模式 | 很好地建立一组服务,用户可以请求他们的服务。 | 请求通常在服务器上的单独线程中处理。由于不同的客户端具有不同的表示,进程间通信会导致额外开销。 |
| 主从设备模式 | 准确性——将服务的执行委托给不同的从设备,具有不同的实现。 | 从设备是孤立的:没有共享的状态。主-从通信中的延迟可能是一个问题,例如在实时系统中。这种模式只能应用于可以分解的问题。 |
| 管道-过滤器模式 | 展示并发处理。当输入和输出由流组成时,过滤器在接收数据时开始计算。轻松添加过滤器,系统可以轻松扩展。过滤器可重复使用。 可以通过重新组合一组给定的过滤器来构建不同的管道。 | 效率受到最慢的过滤过程的限制。从一个过滤器移动到另一个过滤器时的数据转换开销。 |
| 代理模式 | 允许动态更改、添加、删除和重新定位对象,这使开发人员的发布变得透明。 | 要求对服务描述进行标准化。 |
| 点对点模式 | 支持分散式计算。对任何给定节点的故障处理具有强大的健壮性。在资源和计算能力方面具有很高的可扩展性。 | 服务质量没有保证,因为节点是自愿合作的。安全是很难得到保证的。性能取决于节点的数量。 |
| 事件总线模式 | 新的发布者、订阅者和连接可以很容易地添加。对高度分布式的应用程序有效。 | 可伸缩性可能是一个问题,因为所有消息都是通过同一事件总线进行的。 |
| 模型-视图-控制器模式 | 可以轻松地拥有同一个模型的多个视图,这些视图可以在运行时连接和断开。 | 增加复杂性。可能导致许多不必要的用户操作更新。 |
| 黑板模式 | 很容易添加新的应用程序。扩展数据空间的结构很简单。 | 修改数据空间的结构非常困难,因为所有应用程序都受到了影响。可能需要同步和访问控制。 |
| 解释器模式 | 高度动态的行为是可行的。对终端用户编程性提供好处。提高灵活性,因为替换一个解释程序很容易。 | 由于解释语言通常比编译后的语言慢,因此性能可能是一个问题。 |
身边常见企业架构介绍!
Spring MVC 核心架构图
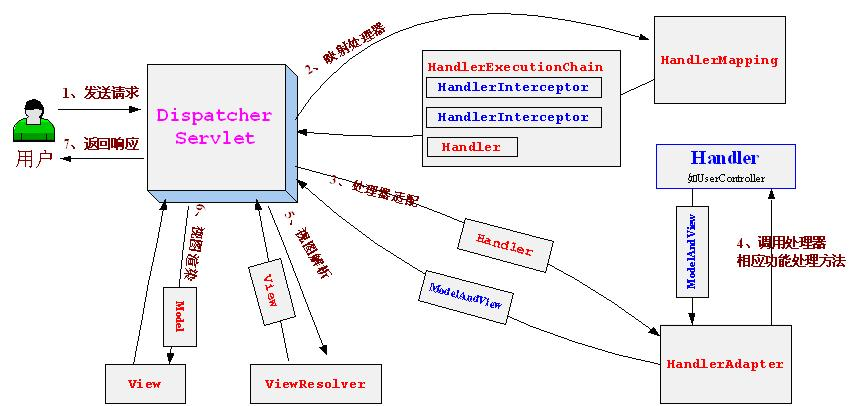
核心架构的具体流程步骤如下:
//前端控制器分派方法
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
int interceptorIndex = -1;
try {
ModelAndView mv;
boolean errorView = false;
try {
//检查是否是请求是否是multipart(如文件上传),如果是将通过MultipartResolver解析
processedRequest = checkMultipart(request);
//步骤2、请求到处理器(页面控制器)的映射,通过HandlerMapping进行映射
mappedHandler = getHandler(processedRequest, false);
if (mappedHandler == null || mappedHandler.getHandler() == null) {
noHandlerFound(processedRequest, response);
return;
}
//步骤3、处理器适配,即将我们的处理器包装成相应的适配器(从而支持多种类型的处理器)
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// 304 Not Modified缓存支持
//此处省略具体代码
// 执行处理器相关的拦截器的预处理(HandlerInterceptor.preHandle)
//此处省略具体代码
// 步骤4、由适配器执行处理器(调用处理器相应功能处理方法)
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
// Do we need view name translation?
if (mv != null && !mv.hasView()) {
mv.setViewName(getDefaultViewName(request));
}
// 执行处理器相关的拦截器的后处理(HandlerInterceptor.postHandle)
//此处省略具体代码
}
catch (ModelAndViewDefiningException ex) {
logger.debug("ModelAndViewDefiningException encountered", ex);
mv = ex.getModelAndView();
}
catch (Exception ex) {
Object handler = (mappedHandler != null ? mappedHandler.getHandler() : null);
mv = processHandlerException(processedRequest, response, handler, ex);
errorView = (mv != null);
}
//步骤5 步骤6、解析视图并进行视图的渲染
//步骤5 由ViewResolver解析View(viewResolver.resolveViewName(viewName, locale))
//步骤6 视图在渲染时会把Model传入(view.render(mv.getModelInternal(), request, response);)
if (mv != null && !mv.wasCleared()) {
render(mv, processedRequest, response);
if (errorView) {
WebUtils.clearErrorRequestAttributes(request);
}
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Null ModelAndView returned to DispatcherServlet with name '" + getServletName() +
"': assuming HandlerAdapter completed request handling");
}
}
// 执行处理器相关的拦截器的完成后处理(HandlerInterceptor.afterCompletion)
//此处省略具体代码
catch (Exception ex) {
// Trigger after-completion for thrown exception.
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, ex);
throw ex;
}
catch (Error err) {
ServletException ex = new NestedServletException("Handler processing failed", err);
// Trigger after-completion for thrown exception.
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, ex);
throw ex;
}
finally {
// Clean up any resources used by a multipart request.
if (processedRequest != request) {
cleanupMultipart(processedRequest);
}
}
}核心架构的具体流程步骤如下:
1、 首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
2、 DispatcherServlet——>HandlerMapping, HandlerMapping将会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象、多个HandlerInterceptor拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
3、 DispatcherServlet——>HandlerAdapter,HandlerAdapter将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
4、 HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView对象(包含模型数据、逻辑视图名);
5、 ModelAndView的逻辑视图名——> ViewResolver, ViewResolver将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
6、 View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
此处我们只是讲了核心流程,没有考虑拦截器、本地解析、文件上传解析等,后边再细述。
近段时间以来,通过接触有关海量数据处理和搜索引擎的诸多技术,常常见识到不少精妙绝伦的架构图。除了每每感叹于每幅图表面上的绘制的精细之外,更为架构 图背后所隐藏的设计思想所叹服。个人这两天一直在搜集各大型网站的架构设计图,一为了一饱眼福,领略各类大型网站架构设计的精彩之外,二来也可供闲时反复 琢磨体会,何乐而不为呢?特此,总结整理了诸如国外wikipedia,Facebook,Yahoo!,YouTube,MySpace,Twitter,国内如优酷网等大型网站的技术架构(本文重点分析优酷网的技术架构),以飨读者。
本文着重凸显每一幅图的精彩之处与其背后含义,而图的说明性文字则从简从略。ok,好好享受此番架构盛宴吧。当然,若有任何建议或问题,欢迎不吝指正。谢谢。
1、WikiPedia 技术架构
WikiPedia 技术架构图Copy @Mark Bergsma

- 来自wikipedia的数据:峰值每秒钟3万个 HTTP 请求 每秒钟 3Gbit 流量, 近乎375MB 350 台 PC 服务器。
- GeoDNSA :40-line patch for BIND to add geographical filters support to the existent views in BIND", 把用户带到最近的服务器。GeoDNS 在 WikiPedia 架构中担当重任当然是由 WikiPedia 的内容性质决定的--面向各个国家,各个地域。
- 负载均衡:LVS,请看下图:
。
 。
。2、Facebook 架构

Facebook 搜索功能的架构示意图
细心的读者一定能发现,上副架构图之前出现在此文之中:从几幅架构图中偷得半点海里数据处理经验。本文与前文最大的不同是,前文只有几幅,此文系列将有上百幅架构图,任您尽情观赏。
3、Yahoo! Mail 架构
Yahoo! Mail 架构

Yahoo! Mail 架构部署了 Oracle RAC,用来存储 Mail 服务相关的 Meta 数据。
4、twitter技术架构

twitter平台大致由twitter.com、手机以及第三方应用构成,如下图所示(其中流量主要以手机和第三方为主要来源):

缓存在大型web项目中起到了举足轻重的作用,毕竟数据越靠近CPU存取速度越快。下图是twitter的缓存架构图:
关于缓存系统,还可以看看下幅图:

5、Google App Engine技术架构

简单而言,上述GAE的架构分为如图所示的三个部分:前端,Datastore和服务群。
- 前端包括4个模块:Front End,Static Files,App Server,App Master。
Datastore是基于BigTable技术的分布式数据库,虽然其也可以被理解成为一个服务,但是由于其是整个App Engine唯一存储持久化数据的地方,所以其是App Engine中一个非常核心的模块。其具体细节将在下篇和大家讨论。
整个服务群包括很多服务供App Server调用,比如Memcache,图形,用户,URL抓取和任务队列等。
6、Amazon技术架构

可能有读者并不熟悉Amazon,它现在已经是全球商品品种最多的网上零售商和全球第2大互联网公司。而之前它仅仅是一个小小的网上书店。ok,下面,咱们来见识下它的架构。
Dynamo是亚马逊的key-value模式的存储平台,可用性和扩展性都很好,性能也不错:读写访问中99.9%的响应时间都在300ms内。按分布 式系统常用的哈希算法切分数据,分放在不同的node上。Read操作时,也是根据key的哈希值寻找对应的node。Dynamo使用了 Consistent Hashing算法,node对应的不再是一个确定的hash值,而是一个hash值范围,key的hash值落在这个范围内,则顺时针沿ring找,碰 到的第一个node即为所需。
Dynamo对Consistent Hashing算法的改进在于:它放在环上作为一个node的是一组机器(而不是memcached把一台机器作为node),这一组机器是通过同步机制保证数据一致的。
下图是分布式存储系统的示意图,读者可观摩之:

Amazon的云架构图如下:

7、优酷网的技术架构
从一开始,优酷网就自建了一套CMS来解决前端的页面显示,各个模块之间分离得比较恰当,前端可扩展性很好,UI的分离,让开发与维护变得十分简单和灵活,下图是优酷前端的模块调用关系:
这样,就根据module、method及params来确定调用相对独立的模块,显得非常简洁。下图是优酷的前端局部架构图:
优酷的数据库架构也是经历了许多波折,从一开始的单台MySQL服务器(Just Running)到简单的MySQL主从复制、SSD优化、垂直分库、水平sharding分库。

- 简单的MySQL主从复制。 MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其原来图如下:其主从复制的过程如下图所示:
 但是,主从复制也带来其他一系列性能瓶颈问题:
但是,主从复制也带来其他一系列性能瓶颈问题:- 写入无法扩展
- 写入无法缓存
- 复制延时
- 锁表率上升
- 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案。
MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:

然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平sharding呢?
MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:

如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示: 但是,优酷是如何解决跨shard的查询呢,这个是个难点,据介绍优酷是尽量不跨shard查询,实在不行通过多维分片索引、分布式搜索引擎,下策是分布式数据库查询(这个非常麻烦而且耗性能)。

缓存策略
貌似大的系统都对“缓存”情有独钟,从http缓存到memcached内存数据缓存,但优酷表示没有用内存缓存,理由如下:
- 避免内存拷贝,避免内存锁
- 如接到老大哥通知要把某个视频撤下来,如果在缓存里是比较麻烦的
而且Squid 的 write() 用户进程空间有消耗,Lighttpd 1.5 的 AIO(异步I/O) 读取文件到用户内存导致效率也比较低下。
但 为何我们访问优酷会如此流畅,与土豆相比优酷的视频加载速度略胜一筹?这个要归功于优酷建立的比较完善的内容分发网络(CDN),它通过多种方式保证分布 在全国各地的用户进行就近访问——用户点击视频请求后,优酷网将根据用户所处地区位置,将离用户最近、服务状况最好的视频服务器地址传送给用户,从而保证 用户可以得到快速的视频体验。这就是CDN带来的优势,就近访问。
 但是,主从复制也带来其他一系列性能瓶颈问题:
但是,主从复制也带来其他一系列性能瓶颈问题:

